DMR V1
Fine-tuned for e-girl, soft male/female, and deep male/female voices. Works best with clean datasets and the Mangio-Crepe/Crepe pitch extraction algorithm.
Sample Rate: 32k
Download D file | Download G file
A pre-trained model is a base model that has already been trained on a large amount of data. When you train your own voice model, you can start from scratch or you can use a pre-trained model as a starting point.
Using a pre-trained model can save you a significant amount of time and effort, and it can often lead to better results, especially if you have a small dataset.

To use a pre-trained model in Applio:
.pth and .index files.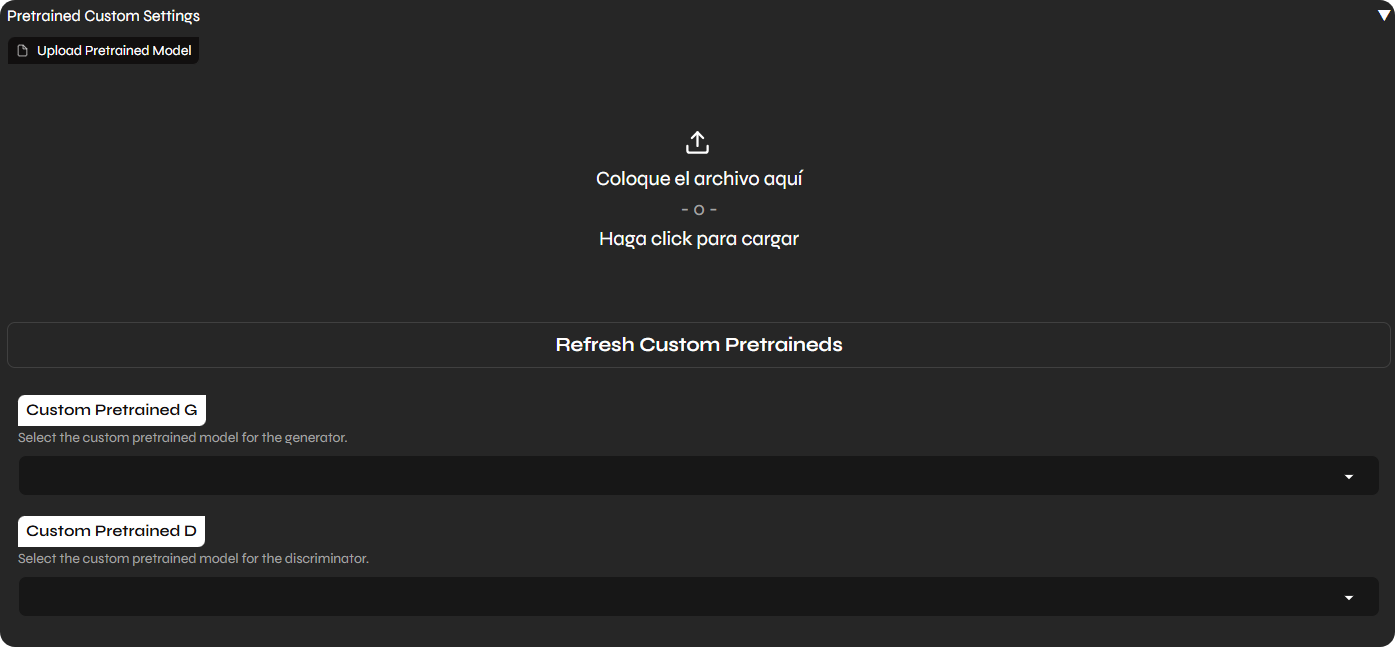
You can also create your own pre-trained models to use as a base for future projects.
When creating pre-trained models, it’s important to use high-quality, non-copyrighted audio.
Here are some popular pre-trained models created by the community.
DMR V1
Fine-tuned for e-girl, soft male/female, and deep male/female voices. Works best with clean datasets and the Mangio-Crepe/Crepe pitch extraction algorithm.
Sample Rate: 32k
Download D file | Download G file
KLM 4.1
Trained on Korean, Japanese, and English data. Ideal for creating vocal guides from short, high-quality studio recordings. Sensitive to noise.
Sample Rates: 32k, 48k
Download 32k D file | Download 32k G file
Download 48k D file | Download 48k G file
Nanashi V1.7
Trained on Brazilian music. Works well for Portuguese and other languages. Handles noise well and requires fewer training epochs.
Sample Rate: 32k
Download D file | Download G file
Ov2 Super
Works well for small, clean English datasets. Trained on bright, emotional voices. Requires fewer training epochs.
Sample Rates: 32k, 40k
Download 32k D file | Download 32k G file
Download 40k D file | Download 40k G file
RIN_E3
Trained from scratch on a large English dataset. Best used with high-quality datasets due to its sensitivity to noise.
Sample Rate: 40k
Download D file | Download G file
SingerPreTrain
Fine-tuned for English singers. Suitable for a wide range of vocal types, from bass to soprano.
Sample Rate: 32k
Download D file | Download G file
SnowieV3.1
Trained on Russian and Japanese data. Helps to improve pronunciation in other languages.
Sample Rates: 32k, 40k, 48k
Download 32k D file | Download 32k G file
Download 40k D file | Download 40k G file
Download 48k D file | Download 48k G file
TITAN
A robust, general-purpose model that gives clean results and handles accents and noise well. Requires fewer training epochs.
Sample Rates: 32k, 40k, 48k
Download 32k D file | Download 32k G file
Download 40k D file | Download 40k G file
Download 48k D file | Download 48k G file